Veri Sistemleri Üzerine
 Görsel: https://filipmanole.com/why-your-business-needs-reliable-scalable-and-maintainable-applications
Görsel: https://filipmanole.com/why-your-business-needs-reliable-scalable-and-maintainable-applications
Eğer okuduysanız, bir önceki yazımda Designing Data-Intensive Applications kitabına başladığımı söylemiştim.
Kitabı okumaya devam ediyorum. Kitabın 1. bölümünden devam ediyorum. Bu bölüm “Foundations of Data Systems” olarak geçiyor.
Şu anda bir uygulamanın reliable, scalable ve maintainable olması konusu üzerine bazı çıktılar elde ettim diyebilirim. Bu yazıda da bu yola girerken, veri sistemleri üzerine düşünebilmeye dair ufak çerez bilgileri size aktaracağım.
Yazıda birazcık Türkçe terim kullanmaya çalışacağım. Durumdan memnun olmazsam, orijinal terimleri kullanma işini bir sonraki yazıya bırakacağım. O zaman hadi özet bilgilerle devam edelim;
Kullanılan Araçları Karakteristik Yapıları ile Kategorize Edebiliriz
Genellikle veritabanları, kuyruklar ve önbellekleri farklı şekillerde çalışan araçlar olarak görürürüz. Dolayısıyla bunları farklı kategorilere de koyabiliriz.
Bir veritabanı ve bir kuyruk (burada mesaj kuyruğu denebilir) benzer şekillerde çalışıyor olabilir. Mesela ikisi de belirli sürelerde veri tutarlar. Ancak veriye ulaşım için kullanılan pattern farklı olabilir. Yani her araç kendisine has bir karakteristiğe, performans koşullarına ve tamamen farklı implementasyonlara sahip olabilir.
Son yıllarda veri depolama(storage) ve işleme(processing) için birçok yeni araç ortaya çıktı. Örneğin, kuyruk gerektiren projelerde kullandığımız Redis ve tıpkı veritabanları gibi dayanıklı olma garantisi sunan kuyruk yazılımları. Örneğin Apache Kafka.
Uygulama Gereksinimleri Arttıkça Çözümler de Değiştirilmelidir
Ayrıca artık şunu söylemekte beis görmeyebiliriz, çoğu uygulamanın isterleri arttı ve gereksinimleri de bir hayli arttı. Yani sadece bir araç kullanarak veri işleme ya da depolama işlemlerini gerçekleştirmek pek de mümkün olamıyor.
Günümüz teknolojilerinde artık beklenen şey, işlerin tek bir araç üzerinde verimli şekilde çalışabilecek şekilde görevlere bölünmesidir. Ve burada farklı araçların da uygulama kodu(application code) seviyesinde birleştirilmesidir.
Uygulama tarafından yönetilen bir önbellek katmanınız olduğunu varsayın. Bu Memcached ya da benzeri bir teknoloji olabilir. Ya da fulltext-search gerçekleştirebileceğiniz bir sunucu hayal edin. Mesela Elasticsearch ya da Apache Solr olabilir. Bu araçlar tamamen ana veritabanınızdan bağımsız yani ayrı bir şekilde çalışıyorlar ve yönetiliyorlar.
Böyle bir bağımsız çalışma ortamında, uygulama kodunuzun indexler ya da önbellek verisini bir şekilde veritabanınızla senkronize etmelidir. Bir örnek görsel aşağıdak gibi gösterilebilir
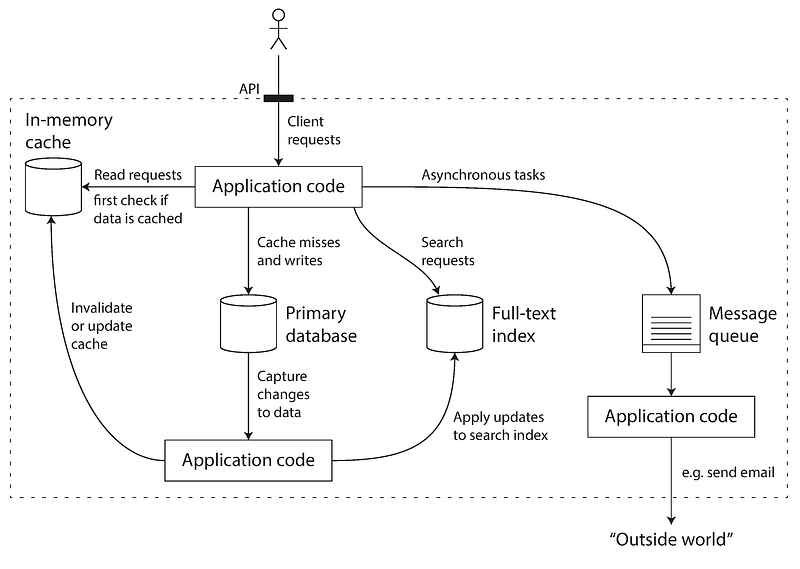 Birden fazla componentin birleşiminden oluşan olası bir mimari yapı.
Birden fazla componentin birleşiminden oluşan olası bir mimari yapı.
Yukarıdaki mimariyi teknik insanlar açısından yorumlayacak olursak, birden fazla componentin birleştirildiğini yani bir araya getirildiğini görebiliriz. Bunlar servisler, interface’ler ya da API’lar olabilir. Günün sonunda bu kadar çok implementasyon client tarafından bilinmek zorunda değil. Ve bu nedenle bu türden implementasyonlar ortalarda pek de “hey buradayım” gibi söylemlerde bulunmazlar.
Sadece Bir Developer Gibi Düşünmekten Kaçınmalıyız! Daha Fazlası Olabiliriz
Örneğin, daha minimal ve genel amaçlarla kullanılabilen componentlerden oluşan yeni bir veri sisteminiz var. Bu veri sistemi birtakım garantiler sunabilir. Mesela önbellek işlemlerinde önemli bir yeri olan invalidate işleminin doğru şekilde yapılacağı ya da güncellenebileceği. Bu sayede client’ların bu verilerle ilgili tutarlı sonuçları göreceğini de bilebiliriz.
Bu şekilde düşünerek ilerlemek bizi sadece bir uygulama geliştiricisi olmanın dışına çıkarır ve aynı zamanda veri sistemi tasarlayan bir kişi gibi düşünmeye de iter.
Tabii bir veri sistemi ya da servis tasarladığınızda, birden fazla zorlayıcı soru ile de karşı karşıya kalırız. Bazı şeylerin sistemsel olarak yanlış gittiğini anladığınızda dahi sağlıklı ve eksiksiz verinin nasıl sağlanacağını düşünürsünüz.
Örneğin sistemde performans sorunları yaşandığında bile client’ların bundan etkilenmemesini nasıl sağlarsınız? Yük testini düşünün. Yük artışı gerçekleştiğinde, ölçeklenebilirliği nasıl sağlarsınız? İyi bir hizmet sağlayıcı olarak bakıldığında mesela API sağlıyorsunuz, bu durumda iyi bir hizmet sağlayıcı nasıl olmalıdır? Yani iyi bir API nasıl olmalıdır?
Bu tarz tasarımları etkileyebilecek birçok şey vardır. Mesela en önemli faktör bu tasarım sürecine dahil olan kişilerdeki beceri ve deneyimler olabilir.
Bir diğer faktör ise bağımlılık konusu. Yani ne kadar nereye bağımlı gibi bir soru, bize tasarımın ne düzeyde etkileneceğini söyleyebilir. Ayrıca deadline gibi kavramlar ve bu sürecin tolere edilebilirliği de yine önemli faktörlerdendir.
Bu konu bu kadardı. Umarım kafanızda data-system ya da veri sistemi üzerine birazcık da olsa bir şeyler oluşturabilmişimdir. Buradaki içerikler kitaptan geliyor.
Okuduğunuz için teşekkür ederim.